



Vulcan Architecture
Vulcan descends from a long line of data management products. The ur-ancestor is the Data Computer created at the Computer Corporation of America (CCA) in the early 1970's. The first morphologically recognizable ancestors are Datatrieve-11 and Datatrieve-32, DEC products from the late 1970's. DSRI evolved from them in the early 1980's. DEC's Rdb products, InterBase, and Firebird are all implementations of DSRI.
Rdb Family and the DEC Standard Relational Interface
The DSRI architecture provided consistent client access to a family of products providing relational data access. The family included two relational databases, Rdb/ELN and Rdb/VMS, networked database servers, database machines, data replication managers, and gateways to third party data management products.
DSRI was an architecturally controlled, formal API implemented by library-based components invoked through a Y-valve. The Y-valve was a software router. Diagram 1 shows the organization of a single client with simultaneous access to one old InterBase database, a local Oracle database, a local Rdb Database, and two local InterBase databases.
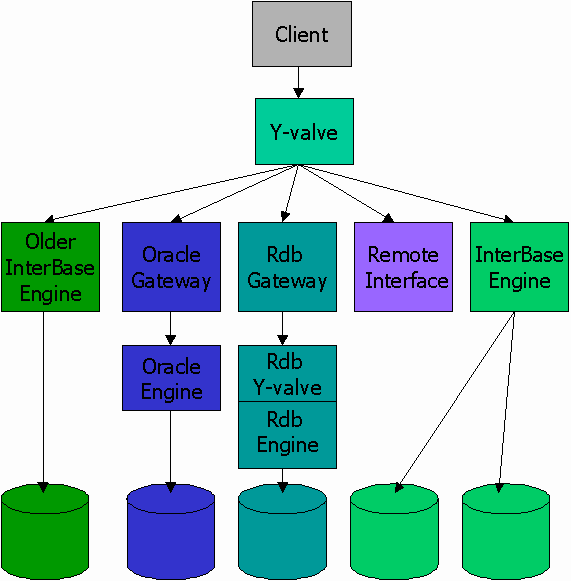
When it received an "attach database" or "create database" call, the Y-valve loaded and polled DSRI service libraries until a service agreed to handle the connection. The Y-valve dispatched subsequent calls on that connection to that service. The Y-valve performed no data management functions except executing the two-phase commit protocol for multiple database transactions, and routing client calls to the appropriate service. In the DEC family of products, each service was a separate shared library that implemented the functions defined by the DSRI standard.
The DSRI architecture used a service called the "remote interface" to implement remote database access. When polled by the Y-valve for an "attach database" call, the remote interface examined the database filename string for a node name. If node name was present, the remote interface attempted to create a connection to a remote server process on that node and establish communication.
If communication was established, the remote interface stripped the node name from the database name and passed the result and any attachment parameters to the remote server. The remote server passed the attach call along to its local Y-valve, and the process repeated on the server node. If the server node Y-valve found a service willing to accept the attachment, it returned a success message to the remote interface, which returned success to the Y-valve, which returned success to the client program. The line protocol between the remote interface and remote server was not part of the architecture, and was a private detail of the implementation.
Diagram 2 shows the same client accessing a local Oracle, a local Rdb, two local InterBase databases and a remote server that gives access to another Oracle, another Rdb, and two more InterBase databases.
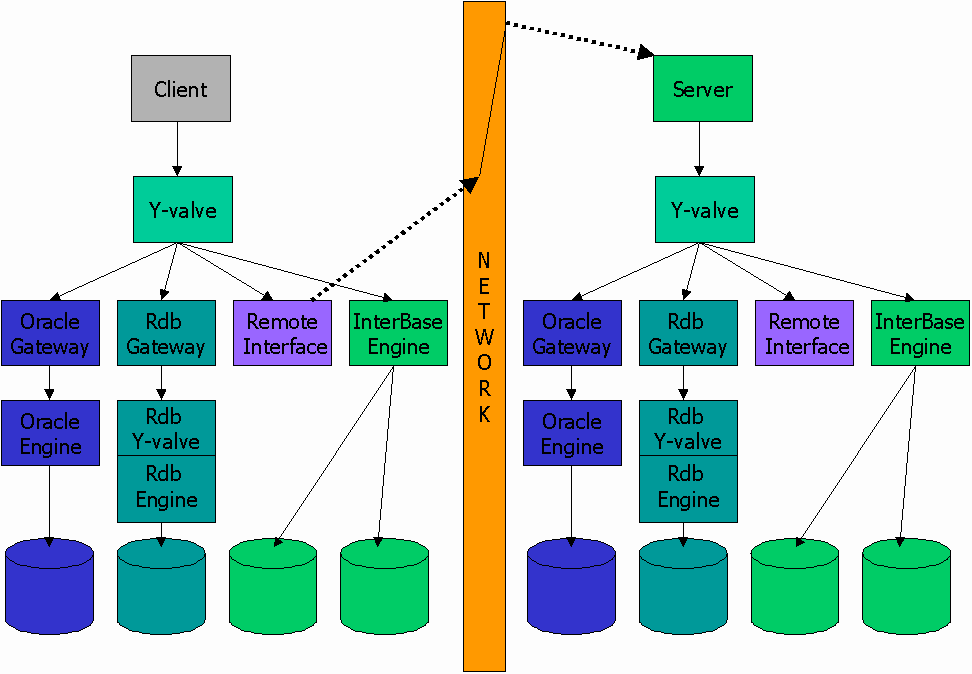
The name for the Y-valve, the remote interface, and the remote server was plumbing - components through which data flowed with minimal processing. The actual database systems were known as engines. Then engines knew all about database files, the semantics of data manipulation languages, and concurrency control. However, they were utterly ignorant about plumbing. In the DSRI architecture, no component saw the big picture. Each piece, the Y-valve, the remote interface, the remote server, engines, gateways, and data distributors managed by a single well-defined function.
InterBase and the Open System Relational Interface
InterBase generalized and implemented the DSRI as an open architecture named OSRI, the Open System Relational Interface. OSRI differed from DSRI in minor ways, primarily message encoding and the format of the date data type.
InterBase was architecturally parallel with DSRI, but differed in implementation details. While the Y-valve and data managers in InterBase were logically separate, the general absence of dynamic libraries on Unix systems in the mid 1980's required static linking of the Y-valve and data managers.
Diagram 3 shows a multi-client "classic" system, using the original architecture. Each client made its own connection to each database through shared libraries linked with its process. In a general way, this was equivalent to a "thread per connection", and let the operating system schedule processes.
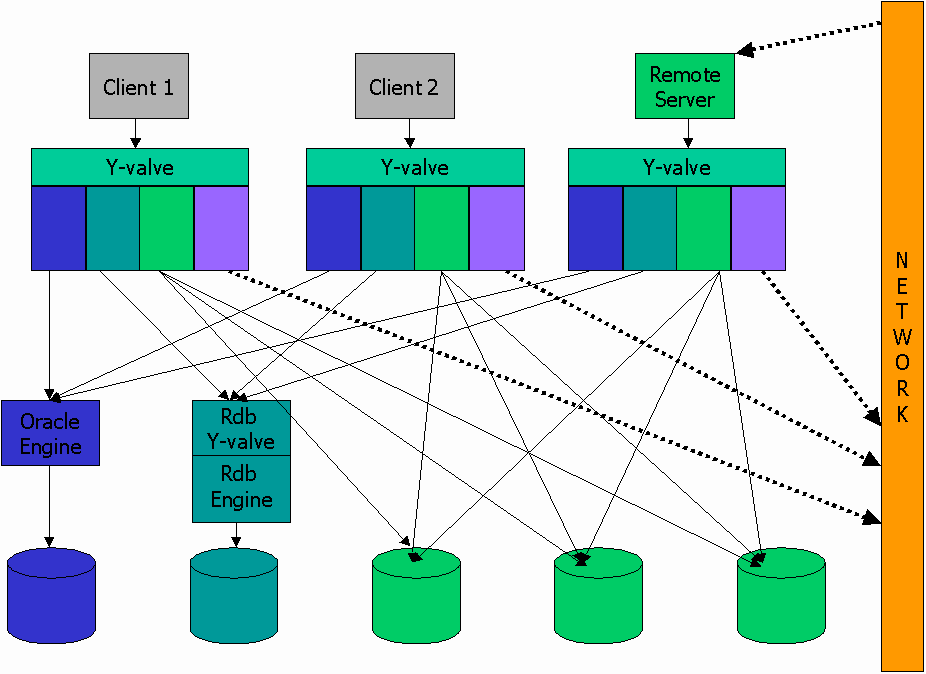
Before version 4 (the first Borland version), the InterBase database engine normally ran in the user process context. A lock manager synchronized access to shared database files. If the file name contained a node name or referenced a file on an NFS mounted file system, the system would transparently shift to the remote database. The alternative to running the database engine in a program's process context was linking the program against a "pipe server" library. In that case, the database engine ran as a forked process. Although the mode of operation was different, the in-process database engine, the engine used by the pipe server, and the engine used by the remote server were identical. The engine code was unaware of the environment they were running. The Y-valve, network interfaces, protocols, and servers were plumbing that transported API calls to the library, process, and across node boundaries. As in the DEC architecture, the plumbing had no effect on the actual operation of the database engine.
InterBase originally supported two data manipulation languages, SQL and GDML (Groton Data Manipulation Language) based on the DEC Datatrieve language and Data Language from CCA. Interactive tools and language preprocessors supported both languages. InterBase version 2 added dynamic SQL as a client side library. The DSQL API implemented the published DB2 dynamic SQL API. By policy, InterBase implemented only standard SQL. Extensions and embellishments were restricted to GDML.
The InterBase engine pre-dated threads and Unix SMP. Version 3 was the first to add thread support to improve concurrency on servers. We wrote our own VMS threading package. The thread implementation used a single database engine mutex, seized on entry to the database engine, released it before I/O or lock operations, and seized again before continuing.
The InterBase server could run as a single-client server (shared file, lock synchronized) process, or as a single instance, multi-client server, or as multiple instances of a multi-client server. On platforms that supported threading, the multi-client server could run single or multi-threaded. The differences, however, were in the server process itself, not the database engine.
InterBase: The Borland Years
Ashton-Tate completed its staged acquisition of InterBase Software Corporation in 1991. Under the terms of the agreement, InterBase remained in Massachusetts with its organization intact except for Jim Starkey. Within six months, however, Ashton-Tate was itself acquired by Borland. Borland dissolved the InterBase organization, reconstituting it on the west coast. Fewer than a dozen of the 65 InterBase employees accepted employment with Borland, including only two engineers. Ashton-Tate had acquired InterBase, in part, to become a full service database company. Borland focused exclusively on the PC platform, and viewed non-PC platforms as distractions.
Borland immediately shed the Oracle and Rdb gateways, the GUI and forms products, after-image journaling, and half the Unix ports. The most significant changes, however, were the shift from in-process database engine to a central server, and dropping GDML. A new, SQL-like trigger and stored procedure language replaced the GDML trigger language. A number of features, like the ability to return a value from an insert statement, were lost.
Beginning with version 4 of InterBase, the database engine became primarily a server, not linked to the user library. The Windows client library appended a "localhost:" to all local database filenames, forcing all client access to go through a central server. To support this, Borland introduced the "SuperServer" architecture.
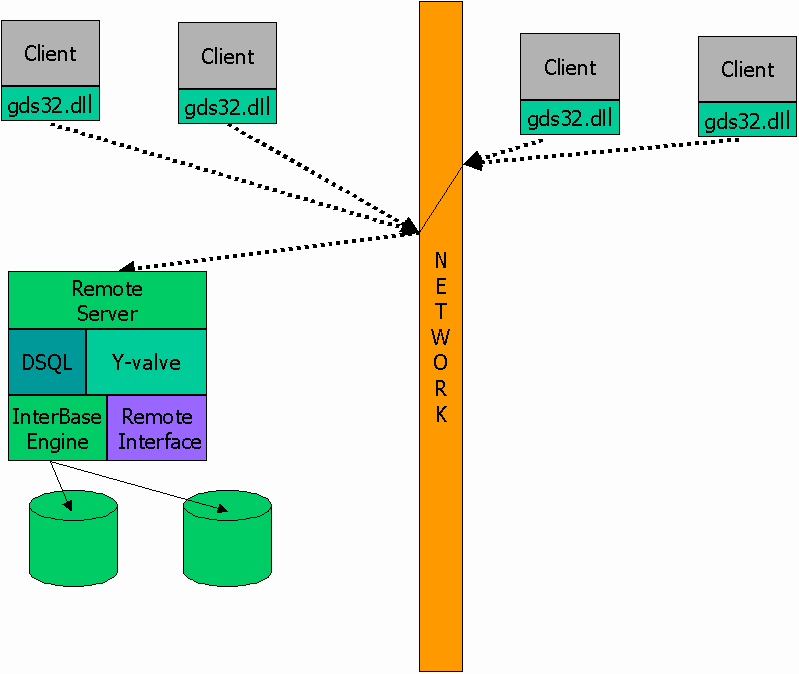
SuperServer differed from the original multi-threaded server in two ways. First, the SuperSserver held a monopoly on access to a database file, banishing shared access. Second, although SuperServer maintained the original external lock manager, it also implemented a second, lighter weight internal locking mechanism. Oddly enough, the SuperServer retained the single database mutex, and never became truly multi-threaded.
Because some Unix platforms had no support for threading, Borland retained the shared file/lock synchronized engine to support one server process per connection, which became know as "classic". On Unix platforms, classic InterBase continued to support in-process database access. The Borland development group dropped the previous architectural rules that specified a single engine that plumbing reconfigured into, server, local access, and remote interface. Instead, Borland introduced conditional code in the database engine code for each option. As a result, a single code base could build three distinctly different engines. Borland also retained abandoned ports and failed engineering projects as conditional code, further disguising any semblance of software architecture.
Borland also re-architected the dynamic SQL component. During the InterBase years, DSQL was a clean layer on the client API. To improve performance, Borland moved DSQL from the client to the server. Rather than integrating it into the database engine, they stuck it as a wart on the Y-valve. DSQL ran partially outside the engine and looped back into the Y-valve for database access. Because DSQL API was not amenable to remote protocols, Borland defined a multi-tiered set of DSQL APIs. The client library translated the documented API into a second set of message-oriented calls. The Y-valve interpreted some and passed others by line protocol to a remote server.
These changes blurred component boundaries, created a proliferation of ad hoc entrypoints, exposed database engine code that was shared with the utilities but could not compile outside the engine, and bred several generations of ill-considered exported services. The boundary between Y-valve and database engine vanished. Thread management functions migrated from the engine to the Y-valve. Integration with the threaded Y-valve required that the remote interface reproduce the engine threading conventions exactly. Integrating operating utilities as services forced them to emulate the same threading conventions.
The original OSRI/DSRI architecture allowed several versions of the database engine to coexist gracefully. That feature made the transition across versions with different on-disk structures nearly seamless. When a client program called "attach database", the Y-valve polled to the most current engine first, and if that failed, then the next older version, and so on. As a result, a client program could connect to new and old databases simultaneously, using the engine version designed for the on disk structure. Borland's integrated Y-valve/database engine broke that architecture. As a consequence, Borland was forced to make the database engines straddle major versions, further complicating the engine code and restricting the scope of changes to the on-disk structure.
Firebird Version 1
Borland released the InterBase source in the summer of 2000, then abandoned it. A group of InterBase users coalesced to support the product as an open source project under the name Firebird. They were soon joined by the principals of IBPhoenix, a company originally sponsored by Borland to support open source InterBase, and then abandoned along with the whole open source concept.
Firebird version 1 was a "names changed" release of InterBase version 6. Firebird version 1 fixed a large number of pre-existing bugs, introduced some minor features, but was otherwise interchangeable with InterBase V6.
Firebird Version 1.5
Firebird V1.5 translated the Firebird V1 code base from C to C++ without significant architectural change aside from necessary syntax changes and replacing C setjmp/longjmp with C++ exception handling. Like Firebird V1 and most other large software projects, Firebird V1.5, took substantially longer than expected. A number of minor changes and enhancements appeared despite the policy to the contrary. Firebird 1.5 did not attempt to introduce object oriented design technology. However, Firebird 1.5 did introduce non-OO C++ esoteria in replacing the memory management and configuration file management functions.
A down side to Firebird V1.5 is that the development group opted for generally low levellow-level compiler optimization, limiting portability.
Vulcan
The goals of the Vulcan branch of Firebird are superficially simple:
- Support for 64 bit machine architectures
- High bandwidth embedded use
- Enhanced SMP performance
The first two are simple and straightforward. The last is not. The root of the SMP performance problem is that Firebird is thread-safe, but it really is not multi-threaded. Firebird, like InterBase, uses a single mutex to control all engine data structures. Only one thread can run at any time, so Firebird gets no benefit of multiple processors. Worse, scheduling a thread on a different processor invalidates its cache. As a result, Firebird must ordinarily enforce processor affinity at the operation system level, often screwing up the entire system.
The fix, in concept, is simple. Replace the single mutex with read/write synchronization locks on specific data structures and page buffers, and elimination of the processor affinity code. In theory, no new tricks are required since from its creation the InterBase engine was multi-client, multi-process and managed shared data structures.
The primary complication is that the Firebird code base is a mess. Boundaries between components have vanished. Three different conditional engine builds, code in place for handling long obsolete database versions, dead code from failed Borland projects, three generations of threading code, and platform conditionals for machine architectures old enough to vote combine to frustrate improvements.
The actual Vulcan goals are dictated by pragmatics:
- Re-establish the architecture by separating the client library, the Y-valve, the database engine, and the remote interface.
- Move the dynamic SQL implementation from the Y-valve into the engine for performance.
- Reduce the number of engine build options from three to one.
- Disable and remove all obsolete engine threading models in favor a read/write synchronization for SMP performance
- Implement a configuration management system to support a mixed embedded/server environment.
- Make the code portable and 64 bit friendly.
- Make provision for hybrid 32/64 bit systems
Vulcan is proceeding in two phases. The first phase, in essence, re-establishes the product architecture. The second phase replaces the single mutex threading model with modern thread management technology.
Vulcan Phase 1
The main tasks of Vulcan Phase 1 were pulling apart the layers, moving dynamic SQL into the database engine, and making the code portable.
The original Y-valve (prosaically named why.cpp) was beyond repair. Vulcan defined a new "provider architecture". A provider is a loadable library that implements the provider interface and supplies data management services. Like earlier versions of the architecture, the Y-valve polls providers during the database attach operation to find one compatible with a given database name string. The original DSRI Y-valve found providers through built-in library names. The InterBase/Firebird Y-valve uses compiled in tables to identify providers. A system of configuration files identifies Vulcan providers by associating patterns of database names with providers.
Vulcan currently has four providers. These are the Y-valve itself (implemented as a provider for simplicity), the Firebird database engine, the Firebird remote interface, and a nascent OSRI gateway for communication with other InterBase or Firebird versions.
The Vulcan configuration system has several goals. As shipped, it is invisible and emulates the connectivity strategy of earlier versions of Firebird. With minimal work, it can provide database location transparency, and map logical database name strings into full connection names and attributes. The same mechanism provides database access transparency for applications. Changing an environmental variable changes the application from shared server access to embedded use. The configuration system though a system of chained configuration files permits delegating per-database access policy to groups and projects.
The second major element of phase 1 was moving the dynamic SQL component from the old Y-valve into the database engine. This involved three major subtasks. One was to replace the DSQL metadata with the internal engine data structures. Second was splitting DSQL statements into a re-useable, potentially cached compiled statement object and a separate statement instance object. The third was to convert the non-reentrant YACC SQL parser into a thread-safe Bison parser. The implementation required object encapsulation of a half dozen major components, work well worth doing.
Code portability turned out to be a major problem. InterBase supported a wide range of systems; version 1 shipped simultaneously on VMS, Apollo, DEC Unix, and Sun. However, Borland was PC-centric and the Firebird project focuses on Windows and Linux. As a result, the code portability suffered. Some portability problems arose from liberties taken with the C++ language, but most were dependencies on implementation artifacts of C++ "std" libraries. Some code worked on only two compiler versions, Microsoft and Gnu, and then only with platform conditional code. Solaris compilation required complete replacement of a number of Firebird 1.5 modules.
Vulcan Phase 2
Vulcan Phase 1 reestablished the product architecture and portability. Vulcan phase 2 enables parallel execution on SMP systems.
InterBase and Firebird V1.x use the original synchronization designed for a shared server in 1986 when there was exactly one processor per machine. A thread ran until it either required a lock, requested a page read or write, or ran out of its "quantum", an arbitrary block of time. The original design did not include a time limit for threads, expecting that every thread would need a lock or an I/O operation from time to time.
Experience showed that some threads did tend to run purely in the cache for an unreasonable amount of time so now each thread can run for a limited time before giving up the processor to another thread that is ready to run. That slows down the total system performance somewhat, but avoids thread starvation, user frustration, and so on.
Threads never check to see if their quantum has run out unless they are prepared to stop, never in the middle of changing a shared data structure, for example.
What you notice here is absolutely no provision for two threads to run at the same time. On an SMP machine, the fact that one thread is running doesn't, shouldn't, mean that others can't run.
Phase 2 replaces existing thread synchronization code with modern synchronization primitives. Specific synchronization objects protect each internal data structure. Most synchronization objects are read/write locks, generally managed by stack-local objects. Each buffer description block in the database page cache will have a synchronization object. The technology, and in most instances code, have been imported from Netfrastructure, which has supported SMP systems for three years.
Once again, in English. Or what passes for it, I hope. Most of what a thread does has no impact on the actions of other threads, but the engine does have a certain amount of data that threads share between threads. Several threads can read shared data structures at the same time, only one thread should modify any one structure at any one time. And, to be very safe, no thread should read a data structure in mid-modification. These rules are easy to follow if only one thread runs at any one time and completes its modifications before stopping.
To use SMP effectively, the engine must allow threads to run concurrently. One way to keep concurrent threads from stepping on each other is to put read/write locks around shared data structures. If you, or anybody, have a read lock on a shared structure, you can read it with assurance that it will be consistent. If you, or anybody, get a write lock on a shared structure, you can modify that structure knowing that nobody will read it in mid-modification.
Normally, threads will keep a read lock on structures they care about. When a thread requests a write lock on a structure, the engine will notify readers, requiring them to release their locks. Once a thread has released its read lock on a structure, it must re-read the structure before taking any action based on the contents of the structure.
The existing code depends heavily on thread specific data. This dependency began as a single database engine global pointer to the current attachment object, evolved into a thread switched global, and then became thread specific data. Unfortunately, hundreds of places in the code reference thread specific data as high overhead global storage. The use of thread specific data appears to work in Firebird 1.5 context, but is not amenable to analysis or verification.
The first step of phase 2 is to clean out the dependencies on thread specific data. In many cases, function calls can pass the actual arguments required to perform a function. Transforming the code is mechanical, but time consuming and tedious. Other cases proper exception handling avoids the need for thread specific data. The net result is a higher performance, more robust, more malleable code base.
The second step is to deactivate all existing thread and IPC mechanisms, temporarily leaving the code non-thread safe, then activate modern, encapsulated synchronization objects which are already in the code.
The third step is to identify and protect individual data structures within the engine.
In theory, the changes in Phase 2 are transparent with little or no impact on the core structures and algorithms. In practice, the path of least resistance often runs through object encapsulation of database engine blocks. That path changes object lifetime control from memory pool deletion to standard C++ destructor based resource control.
Most of the mechanical work required for step 1 is complete. Step 2 will to take approximately a month assuming the existence of a suitable multi-threaded test harness.
InterBase was designed for in-process execution synchronized by lock manager. To work in this environment, the page access strategies were designed to be "careful write", meaning that the database on disk is always consistent and valid. The "SuperServer" architecture runs as a single process making it less sensitive to violations of careful write.
Vulcan, like classic, depends on a deadlock free, careful write strategy. If post-InterBase development has not compromised these characteristics, completion of Vulcan phase 2 will be simple and straightforward. If not, the final Vulcan shakedown could be difficult, particularly in a high contention, SMP environment. Deadlocks are obvious, but corrupted data structures are less so. A non-deterministic environment complicates tracing problems backwards. There is no specific reason to anticipate problems in the core system, but prudence dictates that the possibility be considered.