



Reading a Lock Print
By Ann Harrison
Lock Management in Firebird
Locks are a synchronization mechanism used in multi-user environments to keep processes from destroying the integrity of each other's work. Firebird uses both operating system locking and a proprietary lock manager to coordinate database access.
Lock Management and Versioning
'Wait!' you say, 'Firebird doesn't lock records, it uses multi-version concurrency." And that's true. However, there are two types of concurrency in Firebird, one based on transactions and visible to clients and one instantaneous and controlled by the system itself.
The rules for transaction based locking are that locks can be acquired at any point during the transaction but can only be released at the end.
The commit or rollback of the transaction releases the lock. "Two phase locking" is a standard database technique. When used with write locks, it provides a low level of consistency – eliminating dirty reads and writes but nothing more. When used with both read and write locks, it provides a higher level of consistency – but not repeatable read – at the cost of terrible concurrency. That is why Firebird doesn't use record locks as its primary concurrency control.
Firebird does use locks to keep two transactions from writing to the same page at the same time. These locks must be held while the transaction completes its changes to the page. When the changes are complete, the lock can be released. Normally the lock is held until some other transaction needs to use the page because many transactions make several changes to a page before they complete.
Firebird provides external concurrency and consistency control through record versions. It maintains the consistency of the on-disk structure through locks and careful write.
Locking Strategies
Firebird uses the operating system locking services to control access to database files. The operating system lock prevents the SuperServer from opening the same file twice under different names. A valuable service, but not interesting.
The interesting part of lock management in Firebird is that provided, in general, by our own lock manager. Our lock manager is modeled on the VAX/VMS Distributed Lock Manager which handled locks in a VAX Cluster.
Like contemporary clusters, a VAX Cluster is a group of machines that share access to disks but not memory. Over time, the InterBase lock manager drifted from the VMS lock manager and everyone (nearly everyone) drifted away from VMS.
The mechanism used to create software locks varies, but for Firebird, a lock is represented by structures in memory. One is the object (or concept) to be locked. The others are requests for locks and owners. Each request block indicates whether or not the requester can share the object with others. Each object has a list of some number of request blocks that are currently holding locks on the object and a second list of some number of request blocks that are waiting for the lock. The owner block represents a process, attachment, transaction or the database itself asking for a lock. The owner block contains enough information to alert the owner that the request was granted or that a lock it is holding blocks some other owner's request.
The lock manager is a memory region containing lock blocks, request blocks, owner blocks, and other useful blocks. The lock manager also contains manipulation routines that request, acquire and release locks on resources. It is convenient to describe and think about the lock manager as a separate entity with which transactions using the database communicate rather than as subroutines in each process. That's the way it works in SuperServer. In classic, owner’s line up to get control of the lock table so their lock management code can queue, grant, and release locks. SuperServer is also somewhat more complex than this description because in addition to locks, it has "latches", which co-ordinate changes by concurrent transactions.
Lock Modes or why we do it ourselves
Every operating system offers some synchronization mechanism. Why does Firebird implement its own lock management? Other mechanisms generally offer two states: free or busy. Firebird uses six variants on busy. Free is indicated by zero. One, a null lock, indicates an interest in the object but no restrictions on others' use of it. A null lock prevents the object from being deleted. Two is a shared read, which allows writers. Shared read is the normal mode for table locking. Three is protected read which allows other readers, but not writers. Protected read is the normal mode for locking a database page that is in cache and has not been modified. Four is protected write, which allows shared readers and null locks and nothing else. Protected write is used for consistency mode (table stability) and for locking a database so normal users can not access it.
Lock Table Addressing
In the classic architecture, different owners will map the lock table to different addresses, so addressing within the lock table must be self-relative. Self-relative addressing is also used in the SuperServer lock manager to simplify maintaining two code-bases in one.
Using a lock print
Determining an optimal Hash Slots value
Lock blocks are located through a hash table indexed by key value. By default, the table is 1009 slots wide (Firebird 2.5). Lock blocks are linked in chains dangling from the hash slots. Since the chains are searched sequentially, systems that lock a large number of objects may need a wider hash table to keep the chains of reasonable length.
Check this line in the lock table header block:
Hash slots: 101, Hash lengths (min/avg/max): 10/ 50/ 200
If you see numbers like this, with the average length of a hash chain over 20, you should change the configuration parameter LockHashSlots to a larger prime number. Non-primes do work, but get less even results from the hash algorithm.
Monitoring lock table space
The lock table header block also reports on the size of the lock table and number of bytes used of the space allocated:
Length: 1048576, Used: 1043920
The used space includes blocks on the lock, request, and owner free lists, so the space used can approach the length of the memory allocated without necessarily causing a problem. However, if the difference between the two is less than 1000, you should consider increasing the lock table size by changing the value of the configuration parameter LockMemSize. The parameter that controls the amount of memory available to the lock table.
Locating a blocking process
In the classic architecture, a process that fails to respond to a blocking signal will eventually hang the entire database. A lock print will give you the PID of the blocking process. The first step is to create a lock print using the –w switch. That will show you which owner processes are waiting for which others. If you need to know what resources are creating the conflict, you can create a full lock print, and look for the owners you know are involved, then their request blocks that show pending requests, then the lock blocks for those requests.
Static Lock print
Firebird includes a utility that prints out the contents of the lock table in a (more or less) humanly readable fashion. If we ever get around to it would also store the same information in a database. This paper attempts to explain how to read a lock print. The lock print utility is called fb_lock_print.
Why?
Reading a lock print is useful when you think that there might be a locking problem in the database. Terrible messages from the lock manager, transactions that stick, the inability of anybody to attach the database, or a queasy feeling that nothing else seems to fix are general reasons for suspecting problems in the lock table.
Learning how to read a lock print also teaches the ambitious student about the inner workings of Firebird.
What is fb_lock_print?
The program fb_lock_print is included on all Firebird kits to analyze problems involving the lock manager. The Firebird lock manager is specific to a computer. Each computer that has a database open will have exactly one lock table. Regardless of architecture, all databases on a computer share a lock table. Computers running only remote clients will not have a lock table. The lock table is a section of shared memory that describes all resources that are locked, all requests from owners to lock resources, and all owners that have requested locks. When all database activity on a node ceases the lock table is deleted. The block types in the lock manager are:
SRQ : Self-relative queue. Contains a forward pointer and a back pointer, both relative to the SRQ itself. These blocks are the glue of the lock table are not explicitly printed by the lock printer.
LOCK_HEADER : Describes the lock table itself.
SHB : Secondary header block. A hack for moving from 3.1 to 3.2 that never got cleaned up. That move added the ability to undo partial updates to the lock table.
OWNER : Describes a process, transaction, attachment, or the database that holds or has requested locks. This was called process before the SuperServer added new entities, which can claim locks.
REQUEST : A request (pending or satisfied) from an owner for a lock on a resource.
LOCK : A resource (database, relation, etc.) that can be locked by one or more owners
HISTORY : A description of the 10 most recent lock manager requests.
Lock print switches
The fb_lock_print program accepts a number of switches. When no switches are provided, fb_lock_print prints summary information describing the lock header and the owners communicating with the lock manager.
-a prints the contents of the lock table including the lock header, lock blocks, owner blocks, and request blocks. A lock block represents a resource that can be locked (database, transaction, relation, database page, etc.) and identifies owners that have or have requested a lock on the object A request block describes a request by a process for a lock on a resource. A request block may represent either a granted lock or a pending request for a lock.
-c indicates that the lock table should be copied rather than used live. The copy is quick and produces a static snapshot of the lock table. It will, however, stop all database access on the computer while it runs.
-f specifies that analysis should be done on a named file rather than the live lock file.
-h prints only the history.
-i begins interactive mode, which is very interesting, but needs its own section.
-l prints only lock blocks
-n indicates that there is no bridge. A bridge is an alternate older version of InterBase/Firebird running on the same computer under the Y-valve. There hasn't been a bridge since InterBase V4.
-o prints owner blocks
-p prints owner blocks – they used to be called process blocks.
-r prints request blocks
-s prints a series.
-w prints the waiting on graph, that is to say owner blocks with waiting requests, who they are waiting for and who those owners are waiting for and so on.
Ordinarily when you request a full lock table print, you supply an output file like this:
"fb_lock_print -a > lock.txt"
because the results are quite long. In some versions, a lock print on Linux is infinitely long, which makes it less useful than it might otherwise be. If you find a lock print running for more than a minute or two, or find that it is filling your disk, kill it.
The blocks are listed in the order of the internal lists. New blocks are put at the head of the list, so a newly minted lock table will be shown with blocks in reverse numeric order. As lock, request, and owner blocks are released and reused, the order becomes thoroughly scrambled. A text editor is very useful for chasing through the relationships.
The lock header is always first followed by the first owner block, followed by all the requests for that owner. Each owner in the chain is printed with its requests. The locks follow all owners and request. The last items are the history records.
The following is an example from a very simple static lock print. It represents a database that has just been created and is being accessed by a single copy of ISQL using the SuperServer architecture on Windows. First, we'll consider only the lock header.
(1)LOCK_HEADER BLOCK
(2)Version: 114,(3)Active owner: 0, (4)Length: 32768, (5)Used: 12976
(6) Semmask: 0x0, (7) Flags: 0x0001
(8)Enqs: 10, (9)Converts: 0, (10) Rejects: 0, (11) Blocks: 0
(12)Deadlock scans: 0, (13)Deadlocks: 0, (14) Scan interval: 10
(15) Acquires: 36, (16) Acquire blocks: 0, (17) Spin count: 0
(18)Mutex wait: 0.0%
(19)Hash slots: 101, (20)Hash lengths (min/avg/max): 0/ 0/ 1
(21)Remove node: 0, (22) Insert queue: 0, (23)Insert prior: 0
(24)Owners (5): forward: 12056, backward: 11628
(25)Free owners (4): forward: 11804, backward: 12232
(26)Free locks(1): forward: 11560, backward: 11560
(27) Free requests (1): forward: 12116, backward: 12116
(28)Lock Ordering: Enabled
LOCK_HEADER_BLOCK (1) The block that describes the general shape and condition of the lock table. Each lock print will include exactly one lock header block.
Version (2) The lock manager version number. 114 is the current version for SuperServer. The current lock table version for Classic is 4. These may increase over time, as we need to add information to the lock table blocks.
Active owner (3) The offset of the owner block representing the owner which currently has control of the lock table, if any. In this case, no process is writing to the lock table, so the Active Process is 0.
Length (4) Total space allocated to the lock table in bytes.
Used (5) The highest offset in the lock table which is currently in use. There may be free blocks in the table between the beginning and the used point if owners have come and gone. Free blocks will be reused before new blocks are allocated out of the space between the "used" offset and the end of the lock table.
Semmask (6) Pointer to an SMB block which contains a long word that represents semaphores in use on systems that use static semaphores (e.g. Posix). If no semaphores are available, the lock manager will loop through the owner blocks, looking for one that has a semaphore that it's not using. Failing that, the system returns the error "semaphores are exhausted" – meaning that all the semaphores compiled into the system are in use.
Flags (7) Flag bits in the lock header block that describe general conditions in the block. Two flags are defined, LHB_lock_ordering and LHB_shut_manager. LHB_lock_ordering corresponds to a configuration setting maintained to allow some application to continue to use a lock assignment strategy that has been deprecated. Early versions of InterBase would grant a request for a read lock if the current state of the lock was compatible, even if there was a request for a write lock pending. Reads went flying through, but in a busy system, writes could be starved. The current default is that locks are granted in the order requested which slows down reading but allows writes to happen in finite time. LHB_shut_manager indicates that the database is shutting down and the lock manager ought not to grant more requests.
Enqs (8) Requests for locks (enqueue requests) that have been received. This number includes requests that cannot yet be satisfied and requests that can be satisfied immediately, but not requests that have come and gone.
Converts (9) Requests to increase the level of a lock. A process which holds a lock on a resource will request a mode change if its access to the resource changes. For example, a transaction in concurrency mode, which has been reading a table and decides to change data in the table will convert its lock from shared read to shared write. Conversions are very common on page (bdb) locks because a page is usually read before being altered. Conversions move from a lower level lock (e.g shared read) to a more restrictive level (e.g. exclusive).
Rejects (10) Requests that cannot be satisfied. These may be locks requested in "no wait" mode, or they may be requests which were rejected because they caused deadlocks. Since the access method occasionally requests "no wait" locks for internal structures, you will sometimes see rejects even when all transactions run in "wait" mode and there is no conflict between their operations.
Blocks (11) Requests which could not be satisfied immediately because some other process has an incompatible lock on the resource.
Deadlock scans (12) The number of times that the lock manager walked a chain of locks and owners looking for deadlocks. The lock manager initiates a deadlock scan when a process has been waiting 10 seconds for a lock.
Deadlocks (13) The number of actual deadlocks found, A deadlock occurs when Process A, wants a lock on Resource 1 which is held in an incompatible mode by Process B and Process B wants a lock on some Resource 2 which is held in an incompatible mode by Process A. Each owner stands around glowering at the other and neither will do anything to improve the situation, so the lock manager returns a fatal error to one or the other. Deadlocks can also occur with a single resource if both owners start with read locks and request conversions to write locks. However, deadlocks always involve two owners (or two separate transactions) Errors that are returned as "lock conflict" from "no wait" lock requests will not be recorded in the lock table as deadlocks because only one owner is waiting. Errors returned as "deadlock" with a secondary message specifying "update conflicts with concurrent update" are not actual deadlocks either. What has happened in those cases is that one owner has modified (or erased) a record and moved on. Another concurrent owner has attempted to modify (or erase) the same record, noticed that the most recent version is one he can't see waited to find out how the other transaction ends up, and found to his disappointment, that the other transaction succeeded. In that case, our patient transaction can't modify the record because it can't find out what its late contemporary actually did.
Scan interval (14) The lock manager waits some period of time after a request starts waiting before it starts a deadlock scan. The default interval is 10 seconds, which may be long considering the change in CPU performance since 1983. Deadlock scans should not be done whenever there's a wait because waiting is normal and scans are not free.
Acquires (15) The number of times a owner – or the server on behalf of a specific owner - acquired exclusive control of the lock table to make changes.
Acquire blocks (16) The number of times a owner – or the server on behalf of a specific owner – had to wait to acquire exclusive control of the lock table.
Spin Count (17) There is an option to wait on a spin lock and retry acquiring the Firebird lock table. By default, it is set to zero (disabled), but can be enabled with the configuration file.
Mutex wait (18) The percent of attempts to acquire the lock table that were blocked. [i.e. ((acquire blocks) / (acquires) ) * 100]
Hash slots (19) Resources are located through a hash table. They are stored based on value – more about that later. By default, the hash table is 101 slots wide. That value can be increased using the configuration file.
Hash lengths (20) Below each hash slot hang the resources (lock blocks) that hash to that slot. This item reports the minimum, average, and maximum length of the chain of lock blocks hanging from the hash slots. If the average hash length is over 15, you should increase the number of slots. Use a prime number. Even if the hash lengths are low, don't decrease the number of slots.
Remove node (21) To avoid the awkward problems caused when the active owner dies with the lock table acquired and potentially half updated the owner records the intention to remove a node from the table. When the operation succeeds, the owner removes the remove notation. If any owner finds a remove notation that it did not create, it cleans up.
Insert queue (22) This is the equivalent of the remove node entry above, except that this is the node being inserted.
Insert prior (23) To clean up a failed insert, you not only need to know what you were putting in, but also where. This is where.
Owners (24) The number of owners that have connections to the lock table. Only one of those owners can update the table at any one time (the "active owner"). Other owners hold and wait for locks. In this case there are four owners, none active. Two of the owners are attachments from ISQL. One may be an attachment from DSQL. One is the database itself. Owners are chained forward and backward. An offset in the first and last owner block are included in the "Owners" line. The offset is not the offset of the start of the block, but the offset within the block that contains the pointer to the next owner block. The list of owner blocks is used when the lock manager wants to wander through and get rid of owners that have died without telling everyone and when there is an unresolved blockage and the lock manager decides to poke everyone who might be involved to see if any one has just forgotten the last poke.
Free owners (25) The number of owner blocks which were allocated for owners that have terminated their connections leaving the blocks unused. In this case, there are two, probably transactions involved in creating the database that have since committed. Free owner blocks are also chained forward and backward and the offsets of the first and last free owner blocks are printed if the list is not empty. When the lock manager hears from a new owner, it looks first in the lock header block to see if there are any free owner blocks before allocating a new one. In this case, the list is empty. So the next owner will get a new block. 26. Free locks. The number of lock blocks that have been released and not yet reused. Lock blocks identify a resource (database, relation, transaction, etc.) that has been locked, not a lock on the resource. In this case there is one free lock. Like other free lists this has forward and backward pointers and prints the offsets of the first and last free lock blocks. When an owner requests a lock on a resource that is not currently locked the lock manager looks first to the free lock list in the lock header. If there is a block there with the right key length, that lock block is reused. If not, a new lock block will be allocated out of free space.
Free requests (27) The number of request blocks that have been released and not reused. Request blocks identify a request for a lock on a resource, whether or not it has been satisfied. Like other free lists this has forward and backward pointers and prints the offsets of the first and last free request blocks, and is used in preference to allocating new request blocks.
Lock Ordering (28) As described above, if locks are granted to all owners willing to share even if there are requests from non-sharing owners, the sharers will be handled quickly but the others risk starvation. Lock ordering means taking lock requests in the order received, even if that blocks subsequent requests that could be served immediately. Sounds bad, but it's a good thing.
Owner blocks
(1) OWNER BLOCK 11872
(2)Owner id: 9909104,(3) type: 2,(4)flags: 0x202,(5)pending: 0, (6)semid: 3
(7)Process id: 1868, (8)UID: 0x0 (9)Alive
(10)Flags: 0x02 scan
(11)Requests (3): 12300, backward: 12124
(12)Blocks: *empty*
OWNER BLOCK (1) The block that describes a transaction or other thing which is using the lock manager. The number following the header (11872) is the offset of the process block in the lock table. It is also the id used in the lock header for the "active process" and the beginning of the block into which the forward and backward pointers of the process block list and free process block list point. The value of the list pointers is actually a field in the block which contains the block's own forward and backward pointers. To find requests belonging to this owner, you would search for good old 11872.
Owner id (2) In Classic, the owner is always a process and the owner id is always a process id. In SuperServer, the owner is either the database and the id is the database block, or the owner is the attachment and the id is the attachment block.
Owner type (3) The owner type is a number between 1 and 4. Despite the symbolic definitions in jrd/lck.h, the owner types are always referenced by number:
LCK_OWNER_process = 1, /* Owner is a process */ LCK_OWNER_database =2, /* Owner is a database */ LCK_OWNER_attachment=3, /* Owner is an attachment */ LCK_OWNER_transaction=4 /* Owner is a transaction */
As it happens, the lock owner is never a transaction and the lock manager code implements a special id of 255, which indicates that the lock belongs to a dummy process. Everyone who admires that coding convention please leave the room.
Flags (4) Bits that indicate a specific state. A process can be in several states at once (4 comers?). The owner flag states are:
OWN_blocking 1 /* Owner is blocking */ OWN_scanned 2 /* Owner has been deadlock scanned */ OWN_manager 4 /* Owner is privileged manager */ OWN_signal 8 /* Owner needs signal delivered */ OWN_wakeup 32 /* Owner has been awoken */ OWN_starved 128 /* This thread may be starved */ OWN_signaled 16 /* Signal is thought to be delivered */
The last value applies to own_ast_flags, but is or'ed into the reported flags. The open question is how to interpret the value reported, 202 hex. Beats me. It appears to be an artifact of translating a UATOM (32bit unsigned value) to a UCHAR in the fprintf routine.
The blocking bit means that the process in question has at least one lock that someone else would like to have and can't share. The scanned bit means that the process has been checked in the current deadlock scan. The manager bit means that this is one of those systems that doesn't allow signals to cross groups and so has a privileged lock manager to transmit signals. This owner is that manager. The signal bit indicates that the owner needs to signal and has failed to do so directly. It's a call for help from the manager. Wakeup means that the owner has been poked to release a lock. Starvation happens in Solaris multi-threading and indicates that the process has tried to get the lock table to release a lock more than 500 times without success.
Pending (5) The offset of the lock request block that describes a lock, which the process has requested and has not yet been granted.The Firebird architecture requires that a process limit it's greed to one pending lock request at a time.
Semid (6) The id of the semaphore assigned to this owner. If it could be used, the word "Available" would follow the id.
Process_id (7) The process id of the owner. If the owner is an attachment, database, or transaction, the process id is that of the SuperServer.
UID (8) The user id of the owner process. On Windows, it's always zero.
ALIVE or DEAD (9) The lock printer invokes the routine ISC_check_process_existence and reports the results.
Flags (10) The flag mnemonics. Note that this time the flag value is correct – 2 not 0x202.
Requests (11) Lock requests associated with this process. Lock requests may represent actual locks that the process holds or pending requests for locks. The forward and backward numbers are the beginnings of the forward and backward self relative queues of requests that belong to the process. The numbers are offsets.
Blocks (12) Locks (request blocks) owned by this process that are blocking other lock requests. This list is transitory. It is cleared when the process has been notified that it should release or downgrade its lock, assuming it is able to do so.
Lock blocks
(1)LOCK BLOCK 11988
(2)Series: 1, (3)Parent: 0, (4)State: 6, (5)size: 12(6) length: 12 (7)data: 0
(8)Key: <61><172><21>x<0><0><13><0><145>k<0><0>, Flags: 0x00, Pending request count: 0
(9)Hash que (1): forward: 768, backward: 768
(10)Requests (1): forward: 12300, backward: 12300
(11)Request 12300, Owner: 11872, State: 6 (6), Flags: 0x00
LOCK BLOCK (1) Identifies the block as the description of a resource that has been locked. The number is the offset of that block in the lock table. It identifies the block in the other blocks that reference it.
Series (2) The type of resource this lock represents. The resource types are described below. For reference, their names are:
LCK_database = 1, /* Root of lock tree */ LCK_relation=2, /* Individual relation lock */ LCK_bdb=3, /* Individual buffer block */ LCK_tra=4, /* Individual transaction lock */ LCK_rel_exist=5, /* Relation existence lock */ LCK_idx_exist=6, /* Index existence lock */ LCK_attachment=7, /* Attachment lock */ LCK_shadow=8, /* Lock to synchronize addition of shadows */ LCK_sweep=9, /* Sweep lock for single sweeper */ LCK_file_extend=10, /* Lock to synchronize file extension */ LCK_retaining=11, /* Youngest commit retaining transaction */ LCK_expression=12, /* Expression index caching mechanism */ LCK_record_locking=13, /* Lock on existence of record locking */ LCK_record=14, /* Record Lock */ LCK_prc_exist=15, /* Relation existence lock */ LCK_range_relation=16, /* Relation refresh range lock */ LCK_update_shadow=17 /* shadow update sync lock*/
Series 1. In the classic architecture, a database lock is taken by each process that attaches a database. The first process takes an exclusive lock. The next process notices a conflict and signals the first to downgrade his lock from exclusive to shared. Thereafter, all locks on the database itself are for shared read. In SuperServer, the database takes out an exclusive lock on itself.
Parent (3) The parent of all locks associated with a database is the database lock itself. The only locks, which should have 0 for its parent, are the database locks and journal. The keys that identify locks within a series are meaningful only in the context of a database. The careful Leader will discover one counter example in the abbreviated example and several in the full example. These are bugs, to be corrected in a future version.
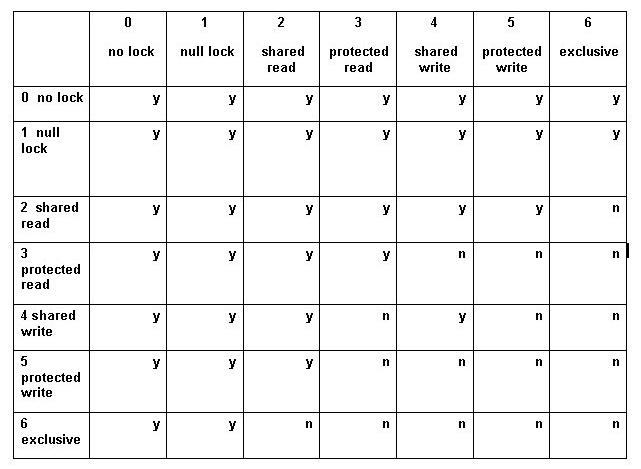
State (4) The highest current state of the lock. Locks have seven possible states. A null lock does little for anybody, but allows a process to acquire a lock on a resource regardless of whether (and how) someone else has locked it. Acquiring a lock allows the locker to read the data from the lock itself. Firebird keeps some important but volatile information in locks, which we will get to soon:
0 - no lock 1 - null lock 2 - shared read 3 - protected read 4 - shared write 5 - protected write 6 – exclusive
Size (5) The length, in bytes, of the portion of the lock block which holds the key. The size is rounded to the natural boundary (word, longword, quadword) for the machine.
Length (6) The actual length of the key, which, because of rounding, may be less than the size.
Data (7) Only journal locks and transaction locks carry data, The data portion is a long word, so it can't be used to store a complete history of the world.
To avoid garbage collecting record versions that another transaction needs, each transaction needs to know the identity of the oldest action any other transaction has seen. When a transaction starts, it stores the id of the oldest transaction still running in the data portion of its transaction lock. It then gets null locks (I told you we'd get back to them) on all concurrent transactions. When a lock is acquired, the contents of the data portion of the lock are returned. The new transaction checks the lock of each existing transaction to discover the identifier of the oldest transaction that any active transaction knows about. Transactions starting up use the lock table as a bulletin board. A cheap way to save and share information.
Key (8) The identifier of the resource being locked. The combination of the key, the series, and the parent uniquely identify the resource being locked.
- For the database the key is the name of the database (or something equivalent), it's printed as if it were a null terminated string, so on systems that use an integer identifier, the key may not print.
- For relation and relation existence locks, it's the relation id.
- For index existence locks, it's the relation id * 1000 plus the index id.
- For a shadow lock, the key is null because there is only one state of shadowing for a database.
- For a transaction, it’s the transaction id.
- For an attachment, it's the attachment id.
Hash queue (9) The beginning and end of the hash queue for the resource key. The lock manager keeps a hash table to facilitate lookup of resources by name. When a process requests a lock on a resource, it identifies the resource by series, parent, and key. The lock manager mashes the values together to create a hash key, then searches the list associated with that hash key value for the desired lock block. The truly over achieving student is encouraged to recreate the hash algorithm by studying the hash queues in the full print out.
Requests (10) First the number of lock requests for this resource, then forward and backward pointers to the request blocks. Note that the backward pointer points to the end of the last block. Finally, the list of requests including the identifier of the request block, the process that made the request, the actual state of the lock with the requested state in parentheses, and finally the request flags. The request flag contains bits which can be combined they are:
1. blocking 2· pending 4. converting 8. rejected
A request is marked as blocking if someone else wants the resource and can't share It given the greedy way it's currently locked. The blocking bit is cleared when a blocking notice has been sent to the piggish process. The pending bit, which is the one most often seen, indicates that the request is waiting for a piggish process to shape up and release it’s lock. You should not see the pending bit set for bdb locks. A request is converting if the process already has a lock on the resource and wants a higher level lock and the conversion can't be done immediately. A lock request is rejected if the request is in "no wait" mode and cannot be satisfied immediately or if granting the request would cause a deadlock.
The state – 6(6) in this case – indicates both the actual state and the requested state of the lock.
LOCK BLOCK 2120
Series: 2, Parent: 1220, State: 2. size: 4 length: 4 data: 0
Key: 5
Hash que (4): forward: 148, backward: 9884
Requests (2): forward: 11432, backward: 5840
Request 11412, Process: 1124, State: 2 (2). Flags: 0
Request 5820, Process: 1124, State: 2 (2), Flags: 0
Series 2 Relation locks A relation lock indicates that the process has read or written to the specified relation in its current transaction, or that it has used the reserving clause on the start transaction statement to declare its intention to read or write to the relation. In this case, both owners are reading the relation. The key field is the RDB$RELATION_ID value for the relation. Note that both requests report their state as 2(2), indicating that they requested and received a shared read lock on the table.
LOCK BLOCK 5384
Series: 3, Parent: 1220. State: 3. size: 4 length: 4 data: 0
Key: 14
Hash que (2): forward: 11468, backward: 220
Requests (2): forward: 7644. backward: 1712
Request 7624, Process: 2556, State: 3 (3), Flags: 0
Request 1692, Process: 1124, State: 3 (3), Flags: 0
Series 3 BDB Buffer Descriptor Block locks A bdb lock is a lock on a database page. These locks are held when two or more owners have attached the database using the classic architecture. They are taken when the process wants to read or write a page and released when the process runs out of buffers in cache and needs to free up space or when another process needs the page. In this example, both owners are reading page 14 (key value) In the Classic architecture, there would be LOTS of series 3 type locks (one for each buffer in the cache of each independent attachment). In SuperServer, most page locks are held within the server and not expressed in the lock table.
LOCK BLOCK 10492
Series: 4, Parent: 1220, State: 6, size: 4 length: 4 data: 585
Key: 585
Hash que (1): forward: 748, backward: 748
Requests (2): forward: 11528, backward: 6416
Request 11508, Process: 1124, State:6 (6), Flags: 0
Request 6396, Process: 2556. State: 0 (3), Flags: 2
Series 4 Transaction locks Each action takes an exclusive lock on its own transaction id when it starts. This block describes the state of the locks on transaction 595. One transaction is waiting for the other to finish so it can decide whether the update it wants to do is legitimate. When the process that holds the lock vanishes from illness, old age, violence, or loss of will to live, its locks will be released and the waiting transaction can read the transaction inventory page and determine the fate of its dead compatriot.
LOCK BLOCK 7176
Series: 5, Parent: 1220, State: 2, size: 4 length: 4 data: 0
Key: 22
Hash que (2): forward: 284, backward: 1556
Requests (1): forward: 2192, backward: 2192
Request 2172. Process: 2556, State: 2 (2), Flags: 0
Series 5 Relation Existence locks The relation existence locks prevent tables from being deleted while any process has a prepared request that uses that table. This lock is the source of "object in use" errors that often occur when attempting to drop tables. When a statement is prepared into a database "request", the compiling process takes out a shared read lock on the existence of the relations and indexes included in the statement. Those locks are held until the request is released or the database is detached.
When a process wants to wipe out a relation, eliminating it from the database rather than just erasing its content, it must get an exclusive lock on the existence of the relation. Because no one can get an exclusive lock on a resource that is locked for shared read by another process, the shared read locks prevent the relation from being destroyed, and so prevent online metadata operations from turning prepared requests to mush.
This particular relation existence lock is on a relation which has an RDB$RELATION_ID of 22.
LOCK BLOCK 1832
Series: 6. Parent: 1220, State: 2. size: 4 length: 4 data: 0
Key:12000
Hash que (2): forward: 2516, backward: 764
Requests (2): forward: 7880. backward: 3536
Request 7860, Process: 2556, State: 2 (2), Flags: 0
Request 3516, Process: 1124, State: 2 (2), Flags: 0
Series 6 Index existence locks The index existence locks prevent indexes from being deleted while any process has saved a request that uses the index. When a statement is prepared into a database "request", the compiling process also takes out a shared read lock on the existence of the indexes included in the statement. Those locks are held until the request is released or the database is detached. When a process wants to delete or deactivate an index, it must get an exclusive lock on the existence of the index.
Because no one can get an exclusive lock on a resource that is locked for shared read by another process, the shared read locks prevent the relation or index from being destroyed, and so prevent online metadata operations from turning compiled requests to sausages. The index existence lock id is 12000 which is the relation id times 1000 plus the index id. This lock records an interest in the existence of index 0 for relation 12.
Series 15 Procedure existence locks These locks are exactly like relation and index existence locks, and serve a similar purpose. The key is the procedure id from the system table RDB$PROCEDURES.
LOCK BLOCK 1352
Series: 7, Parent: 1220, State: 6, size: 4 length: 4 data: 0
Key: <n>...
Series 7 Attachment locks This series is not used currently. It was designed to support dBase record locks, which can exist across transaction boundaries. The algorithm is approximately this:
- You say, lock this record for me.
- Firebird checks that the record includes a dBase_lock field and a trigger that tests the state of the lock and aborts the operation if the lock is not compatible. If one or both are missing, it creates them for you.
- Firebird checks that you have an attachment id, and creates one for you if you don't. You get an exclusive lock on your attachment id.
- Firebird writes your attachment id into dBase_lock field of the record.
When you want to change a record, the trigger reads the lock field in the record and checks to see if it's compatible with your request. It returns:
0 If there's no attachment identified in the dBase_lock field of the record,
1 If there's an attachment but nobody holds the lock on it. This can only happen if the attachment that held the lock has gone to the big attachment round-up in the sky.
2 If there's a valid locked attachment id, and it's yours.
3 If there's a valid locked attachment id, and it's not you. This is the only fatal case.
LOCK BLOCK 1352
Series: 8, Parent: 1220, State: 2, size: 4 length: 4 data: 0
Key: 0
Hash que (3): forward: 1460. backward: 108
Requests (2): forward: 6844, backward: 7152
Request 6824, Process: 2556, State: 2 (2), Flags: 0
Request 7132, Process: 1124. State: 2 (2), Flags: 0
Series 8, shadow locks Every process that attaches to a database takes out a shared read lock on the state of shadowing for the database. If a process wants to add a new shadow file, it converts its lock to exclusive which notifies all other users that a shadow file is about to appear, and they should write changes to that file. This series is used for interprocess communication in Classic. It's also used in SuperServer, more out of habit more than anything.
Other lock series
Series 9 Sweep lock Sweep is a moderately expensive operation and works best if only one thread or attachment does it. The actual sweeper keeps an exclusive lock in this series to avoid conflicts. This series is used for interprocess communication in Classic. It's also used in SuperServer, out of habit more than anything.
Series 10 File extension lock Extending the database file is another operation that doesn't go as well if two transactions try to do it at once. This series is used for interprocess communication in Classic. It's also used in SuperServer, out of habit more than anything.
Series 11 Commit retaining lock This is used only on VMS. It probably marks a place where Firebird has extended the locking semantics to fit its needs and so requires a special hack to work with the VMS lock manager.
Series 12 Expression locks Originally this series was intended to describe expression indexes – how to evaluate them, what the result of the evaluation was likely to look like, etc. For some reason, they're now used when deleting any index.
Series 13 Record locking lock This series indicates that record locking has been requested for a particular table. The first process to request record locking for a table also gets a protected lock on the table. Until that lock is challenged, record locks are kept in the attachment. When a second transaction arrives, the table lock is downgraded to shared and locks are expressed. This series is used only in the deprecated PC emulation code.
Series 14 Record locks This series is also used only in the deprecated PC emulation code and uses the record's dbkey as the lock name.
Series 16 Relation range locks Again, this series is used only in the PC emulation code which has a concept of update ranges.
Series 17 Shadow update This lock series is used to limit to one the number of processes that simultaneously cause processing to roll over to a shadow or disable shadowing.
Conflicts
Here is the lock block that describes the state of lock requests when two transactions attempt to modify the same record. One is waiting for the other to release its transaction lock so the second modifier can decide whether the first modification was committed (meaning that the second attempt will end with an error) or rolled back (so the second attempt can succeed).
LOCK BLOCK 10492
(1)Series: 4, Parent: 1220, (2)State: 6, size: 4 length: 4 data: 585
Key: 585
Hash que (1): forward: 748, backward: 748
- (3)Requests (2). forward: 11528, backward: 6416
- Request 11508, Process: 1124, (4)State: 6 (6), (5)Flags: 0 Request 6396, Process: 2556, (6)State: 0 (3), (7)Flags: 2
1 This lock is series 4, the transaction lock series. If we track back through request 11508 to its owner block, we will find the thread or process that owns this transaction. The database is quite new because the transaction id is only 585. No great surprise there, since the database was created for this paper.
2 The state of the lock, which is held exclusively
3 There are two requests waiting. Note that the forward and backward pointers are not the same as the block offsets that follow. They point to the SRQ blocks that form the actual chain.
4 The first request has requested and received an exclusive lock on the transaction id 585.
5 There's nothing unusual about that request, so its flags are clear.
6 The second request has no lock and has requested a protected read lock on the same transaction. This request will not be satisfied until the exclusive lock is released as part of ending the other transaction. At the moment the second request holds no lock on the resource.
7 The flags indicate that this request is blocked.
Onward to request blocks. This should be easy.
(1) REQUEST BLOCK 7624
(2) Process: 2556, (3) Lock: 5384, (4) State: 3, (5) Mode: 3. (6) Fl ags:0
(7) AST:3afc4c30, (8) argument: 3af776e0
REQUEST BLOCK 11508
Process: 1124, Lock: 10492, State: 6, mode: 6, Flags: 0
AST:0, argument: 3af76a2c
REQUEST BLOCK 6396
Process: 2556, Lock: 10492, State: 0. Mode. 3, Flags: 2
AST:0, argument: 0
1 REQUEST BLOCK. The identifier of this particular request
2 Process. The offset of the process block that describes the process that made this request.
3 Lock. The offset of the lock block that describes the resource being locked.
4 State. The state of the lock which has been granted on the resource. To refresh your memory the states of locks are:
0 - no lock 1 - null lock 2 - shared read 3 - protected read 4 - shared write 5 - protected write 6 - exclusive
In the first two examples, the state is the same as the mode. These are locks, which have been granted. The first was granted in protected read mode, the second in exclusive.
5 Mode. The state in which the lock was requested. In the third example, the lock is pending, so the state is 0 (no lock) but the mode is 3 (protected read).
6 Flags. The request flag contains bit, which can be combined. They are:
1 - blocking 2 - pending 4 - converting 8 – rejected
7 AST. The address of a routine to call if someone wants a conflicting lock on the resource held by this request. Routines to downgrade or release locks are always supplied for locks on the database, the state of shadowing and the bdb's (buffer descriptor blocks, which identify a database page in cache).
The database lock will be downgraded from exclusive (for the first user) to shared read when the second user shows up in the classic architecture. In SuperServer, the database holds an exclusive lock on itself.
The shadow shared read lock is released when another process requests the lock in exclusive mode so it can create new shadow file(s). As soon as the files are created, everyone re-seizes shared read locks on the state of shadowing.
When there is a conflict for a database page, the process that holds the page immediately releases it and downgrades its lock unless the page is actually in the process of being modified. If so, the page is marked as needing to be released as soon as the modification is done.
8 Argument. The address of something that the AST routine will want.
- In the case of a bdb, it's the address of the structure in the process that describes the buffer.
- In the case of the database and shadow locks, it's the address of the dbb, the master block that describes the database.
- In the case of transaction locks, which don't have ast routines it's an oversight.
History
The second to last item in the print out is the history. The lock manager keeps track of the last IO actions it took on anyone's behalf. Here are some sample history records
ENQ: owner = 12056, lock = 0, request = 11696
GRANT: owner = 12056, lock = 12564, request = 11696
CONVERT: owner = 12056, lock = 12564, request = 11696
GRANT: owner = 12056, lock = 12564, request = 11696
DEQ: owner = 12056, lock = 12564, request = 11696
This is a normal sequence. An established owner (12056) requests a lock on a resource. At the time of queuing the request the offset of the lock is not known. The lock is granted on the resource at 12564. The owner then requests to change the level of the lock. That request is also granted. Last, the owner releases the lock completely. This is a typical order of lock acquisition for a page update.
GRANT: owner = 11628, lock = 11744, request = 12516
ENQ: owner = 12056, lock = 0, request = 11512
DENY: owner = 12056, lock = 11744, request = 11512
ENQ: owner = 12056, lock = 0, request = 12408
POST: owner = 11628, lock = 11744, request = 12516
WAIT: owner = 12056, lock = 11744, request = 12408
SCAN: owner = 12056, lock = 11744, request = 12408
POST: owner = 11628, lock = 11744, request = 12516
POST: owner = 11628, lock = 11744, request = 12516
POST: owner = 11628, lock = 11744, request = 12516
DEQ: owner = 11628, lock = 11744, request = 12516
GRANT: owner = 12056, lock = 11744, request = 12408
Here a different owner (11628) is granted a lock on resource 11744. The original owner (12056) queues a request for the same resource, asking to get it with no wait. The lock held by owner 11628 is in an incompatible mode, so that request is denied. Owner 12056 comes back with a different request, asking for the lock again, but willing to wait. The lock manager code pokes owner 11628 on the subject of resource 11744. Owner 12056 is told to wait nicely until things get better. They don't get better in 10 seconds, so the lock manager starts a deadlock scan. That doesn't help, so the lock manager goes back to poking owner 11628. Eventually the pokes get through and 11628 gives up the lock which is granted to 12056.
Event log
History is kept in the lock table in history blocks, which are arranged in two ring buffers, each of which controls 256 history blocks. The first ring buffer hangs off the lock header block and contains the "old style" messages. They are printed under the heading "History". The second group of history blocks hangs off the secondary header block and contains "new style" messages. They are printed under the heading "Event log", and will generally look like this
DEL_OWNER: owner = 12232, lock = 12232, request = 0
DEL_OWNER: owner = 12056, lock = 12056, request = 0
DEL_OWNER: owner = 11872, lock = 11872, request = 0
DEL_OWNER: owner = 11376, lock = 11376, request = 0
DEL_OWNER: owner = 11804, lock = 11804, request = 0
You may also see an entry of this format
ACTIVE: owner= xxxxxx, lock= 0, request= 0
This is unusual and possibly reason for concern. In the Classic architecture, each process updates the lock table on its own behalf. Access to the table is controlled by a mutex. When it acquires the mutex, each process writes its owner-block id into the lock header block. Immediately before releasing the mutex, it removes its id from the lock header block. This message occurs when a process acquires the mutex and discovers that another owner id is already written in the header block. This situation occurs when a process is killed while it has the lock table acquired. The secondary lock header block keeps enough information that the new process should be able to undo any half-completed actions of the previous process.